OCR pour reconnaître et extraire les données des permis de conduire, des livrets d'identité et des cartes à puce
Précision de la reconnaissance améliorée jusqu'à 90 %.

Solution basée sur l'OCR pour capturer et récupérer automatiquement les données à partir de scans de documents
- DéfiIdentification et extraction de données sensibles à partir de scans d'images et facilitation des processus basés sur des documents
- SolutionSolution basée sur l'OCR pour capturer et récupérer automatiquement les données à partir de scans de documents
- Technologies et outilsPython PyTorch Tesseract OpenCV
Client
Le client est un fournisseur sud-africain de solutions de gestion de contenu qui travaille avec les acteurs majeurs de l'industrie bancaire du pays. L'objectif principal du client est d'aider les entreprises à capturer et gérer les actifs de données afin d'améliorer l'efficacité opérationnelle. Pour ce faire, ils intègrent différents outils d'automatisation.
Cette étude de cas mettra en avant notre expertise en vision par ordinateur et l'importance de la reconnaissance optique de caractères (OCR) lors du traitement des numérisations de documents.
Défi : Capturer et dériver des données à partir des scans de documents et faciliter le flux de travail des documents
Le client traite régulièrement de grands volumes de données. La recherche manuelle des données et leur reconnaissance à partir de livrets d'identité, de cartes à puce, de permis de conduire ou de tout autre document est chronophage et pénible. C'est pourquoi le client cherchait une solution de capture et d’extraction de données automatisée. Ils avaient besoin d'un avis d'expert sur l'intégration de l'OCR dans leur système ERP pour traiter des fonctions métier critiques. Mais l'objectif principal était d'exploiter les données issues des numérisations de documents et de réduire leur traitement et leur saisie manuels, car cela prenait beaucoup de temps.
Le principal défi pour notre équipe était de capturer et récupérer des données à partir de scans photo qui varient souvent en orientations, positions, couleurs, arrière-plans et conditions d'éclairage. Nous avons livré un service qui aide à reconnaître les objets dans les scans d'image et à déterminer quelles données doivent être extraites.
Solution : Solution basée sur OCR pour automatiser la capture et l'extraction des données à partir de numérisations de documents
Forte d'une vaste expérience en implémentation de l'OCR, l'équipe DataSqueeze a fourni au client une solution sur mesure qui aide à automatiser les processus métier basés sur les données sur le lieu de travail du client et à améliorer la performance globale du travail.
Notre équipe a étudié la faisabilité d'extraire et de reconnaître des champs de texte tels que le nom, le prénom, l'ID, la date de validité (du/au) à partir des permis de conduire issus des bases de données DMV, des cartes de visite, des livrets d'identité et des cartes à puce à l'aide de l'OCR. Lorsqu'il s'agit de traiter ces types de documents pour exploiter les données, ils sont difficiles à gérer. Dans ce cas, la reconnaissance faciale vient en aide et permet d'extraire des données des permis de conduire endommagés ou des livrets d'identité flous.
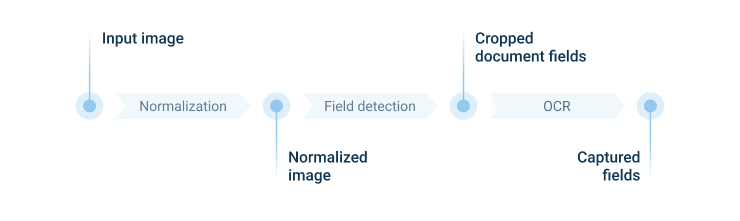
La prochaine étape consistait à découvrir comment utiliser reconnaissance faciale pour identifier le visage d’un individu sur la photo du permis de conduire ou tout autre scan de document. Nous avons commencé à développer une fonctionnalité de prétraitement d'image qui a considérablement amélioré l'efficacité d'un moteur OCR commercial intégré grâce au recadrage, à la rotation et au redressement automatiques. Nous avons également fait évoluer le classificateur de documents existant pour distinguer 3 types de documents : une carte à puce, un livret d'identité et un permis de conduire. Nous avons divisé ce processus en deux phases : la normalisation de l'image et la reconnaissance des champs.
1. normalisation d'image
Le principal défi pour les moteurs OCR est de reconnaître les scans rotatifs, inclinés, assombris et flous ainsi que les scans photo avec un arrière-plan complexe qui entraîne généralement des malentendus et des erreurs. Pour atténuer cela, nous avons formé un modèle pour capturer un document, le recadrer et redresser une image. Cette phase a considérablement amélioré la reconnaissance du pipeline par défaut. En conséquence, nous avons obtenu un document sans aucun arrière-plan correctement positionné.
2. reconnaissance de champs
La prochaine tâche consistait à capturer et identifier les champs requis dans l'image normalisée. Pour ce faire, nos data scientists ont formé un autre modèle de machine learning qui prédit où se situe exactement le champ particulier. Ayant la localisation précise des champs requis, ils pouvaient les recadrer à partir de l'image normalisée et les identifier indépendamment. Cela a donné à notre équipe plus de liberté dans le prétraitement et l'optimisation de la performance du moteur OCR.
Pour reconnaître les champs requis, nous avons appliqué les moteurs OCR intégrés Tesseract ou Captiva.
Examinez de plus près le diagramme des cas d'usage OCR :
Résultat : Solution de capture et d'extraction de données OCR pour réduire l'effort manuel
Ayant une expertise technique approfondie dans le développement solutions de reconnaissance d'images, nos ingénieurs ont livré une solution robuste qui capture automatiquement et extrait les données sensibles des permis de conduire, livrets d'identité et cartes à puce, et augmente l'efficacité opérationnelle globale sur le lieu de travail du client.
Notre solution permet de traiter un scan de document en 2 secondes. 4 scans de documents peuvent être traités simultanément. La précision de la reconnaissance est d'environ 85-90%.
La coopération avec nous a permis au client dans les aspects suivants :
- Reconnaissance automatisée de texte et d'image
- Extraction de données facile et intelligente depuis des documents scannés
- Accélération globale lors du traitement des textes et images numérisés
- Intégration OCR dans le système ERP du client
- Réduction de l'effort manuel dans le lieu de travail du client