Extraction de données efficace depuis le site web pour une gestion améliorée des données
Accès à plusieurs sources de données via l'extraction de données.

-
DéfiScraping de données rapide et précis à partir de multiples sources
-
SolutionMeilleures pratiques pour un scraping web robuste et résilient
-
Technologies et outilsMicrosoft Azure Cloud Services pour l'hébergement d'infrastructure, le réglage et l'administration. Langage Python avec les bibliothèques et frameworks requis (Azure-sdk, Scrapy, Selenium, etc.) pour le processus de scraping et de crawling des sites web
Client
Le client est une organisation non commerciale qui soutient les petites entreprises et les entrepreneurs afro-américains. Elle est fière de fournir des services qui aident les entrepreneurs afro-américains à obtenir des subventions et à réussir dans les compétitions.
Défi : scraping de données rapide et précis à partir de multiples sources
Le client traite régulièrement de grandes quantités de données provenant de diverses sources. La gestion des données est donc devenue une préoccupation pour eux.
Ils voulaient collecter des offres d'emploi, des opportunités de mentorat et de réseautage pour les entrepreneurs afro-américains talentueux provenant de divers sites web et les publier sur leur propre plateforme. Ainsi, les entrepreneurs peuvent facilement découvrir des entreprises appartenant à des Afro-Américains et les soutenir ou localiser les leurs.
DataSqueeze a été mis au défi de développer une solution robuste de scraping de données pour la marketplace du client.
Solution : Meilleures pratiques pour un scraping web robuste et résilient
Notre équipe d'ingénieurs a appliqué son expertise en scraping de données pour permettre une collecte efficace des données provenant de diverses sources.
L'équipe DataSqueeze devait mettre en place l'infrastructure et le flux de code pour le client :
-
Partie Git et CI/CD
Pour la gestion du code, un dépôt AzureDevOps a été utilisé avec une configuration de pipeline qui a permis à notre équipe de construire et pousser des images Docker vers le registre en utilisant un agent de job parallèle.
-
Partie du registre et de l'application Logic
Ensuite, nous avons créé le registre de conteneurs Azure Docker sur le portail Azure pour stocker nos images Docker.
Nous avons ensuite dû créer des instances Docker à partir d'images en utilisant Azure Logic App pour exécuter le code du scraper en parallèle et séparément.
-
Partie du scraper
Au cours de cette étape, l'équipe DataSqueeze a créé des instances de conteneurs avec Logic Apps. Ensuite, nous avons dû donner à chaque conteneur l'accès aux ressources Azure et aux données sensibles telles que les mots de passe, les chaînes de connexion, etc., stockées dans Azure KeyVault.

Pour stocker les sorties du scraper, notre équipe a décidé de créer un Storage Account qui ferait office de dossier cloud pour enregistrer les données extraites. Ensuite, nous avons pu lancer nos scrapers manuellement, mais nous avions besoin d’un peu d’orchestration, d’automatisation et de post-traitement.
-
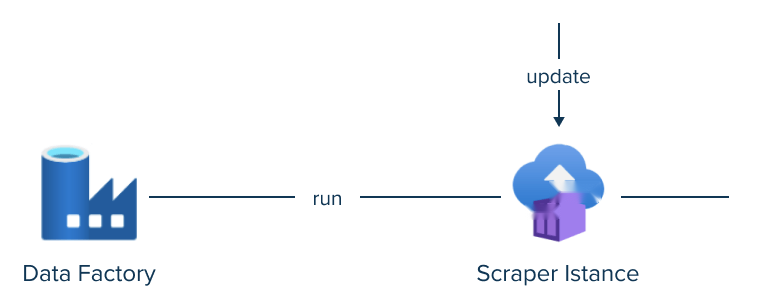
Data Factory et partie orchestration
Nos ingénieurs ont exécuté tous nos scrapers avec un déclencheur temporel et dans une seule exécution de pipeline avec Azure Data Factory.
Le pipeline principal était censé démarrer tous les conteneurs avec des requêtes via l'API Azure, puis exécuter Databricks Carnets pour traiter les données collectées.
-
Databricks
À ce stade, nous faisions le scraping de toutes les données des sites web (car le chargement incrémentiel des données des sites web est impossible ou difficile) et le traitement/sauvegarde complet des données dans la base de données. Avant de charger de nouvelles données dans la base de données, nous avons supprimé les données existantes.
En conséquence, le client a obtenu une solution robuste de scraping de données qui extrait des données de plusieurs sites et annuaires d'entreprises et collecte des informations sur les entreprises fondées par des Afro-Américains, utiles pour les abonnés de la plateforme du client.
Résultat : optimisation du scraping de données pour réduire le temps de traitement
Notre équipe de data scientists et d'ingénieurs a utilisé plusieurs sources pour répondre aux besoins de scraping de données du client.
Notre solution a permis au client de la manière suivante :
- Extraction des données à grande échelle
- Données structurées livrées
- Faible maintenance et rapidité
- Facile à mettre en œuvre
- Automatisation