
Aujourd’hui, la digitization pénètre toutes les sphères de l’entreprise. 2,5 quintillions d'octets de données que les gens créent chaque jour est essentiellement de la donnée non structurée. Qu'il s'agisse d'audio, de vidéo ou de texte, la Big Data (si elle est méticuleusement collectée, reconnue et traitée) peut générer de la valeur commerciale grâce à l'exploitation de technologies de pointe.
Mais peu importe à quel point les machines peuvent être intelligentes, elles ne sont pas capables d'absorber et d'interpréter les informations comme le font les humains via les sens. Pour l'entraînement algorithmes de machine learning et de deep learning, les données doivent être au format numérisé. Donc, solutions basées sur l'IA Pourrait le traiter et le comprendre.
Collecte et capture de données automatisées
La capture de données automatisée implique l'utilisation de technologies permettant aux machines pour capturer des données et le transformer ensuite en informations significatives. Le choix des méthodes de capture de données automatisées dépend du type d'entreprise et des objectifs stratégiques. Voici des exemples qui montrent le rôle clé du Big data pour permettre aux entreprises de prospérer.
La collecte de données automatique est un autre terme que nous pouvons utiliser pour décrire le fonctionnement des systèmes de capture de données automatisée. La technologie derrière la capture de données automatique identifie et capture les données. Les systèmes de capture de données automatisée apportent de la valeur aux entreprises grâce à l'automatisation des processus.
Voici quelques avantages des systèmes de capture de données automatisés :
- Efficacité améliorée
- Réduction de la paperasse et des coûts
- Réduction des erreurs humaines
OCR, OMR, ICR : Quelle est la différence ?
Reconnaissance optique de caractères (OCR) est une technologie bien établie et éprouvée. Une fois que la technologie a bouleversé l'approche traditionnelle de la gestion documentaire, elle reste toujours aussi pertinente.
Comme solution parfaite pour numériser d'énormes quantités de documents papier et électroniques, elle est largement utilisée dans des domaines tels que logistique, santé, finance, banque, gouvernance, et plus encore. Les systèmes OCR polyvalents réduisent efficacement les coûts de capture de données, automatisent les tâches manuelles routinières et remplacent les employés humains dans les tâches répétitives. Bien que le résultat nécessite une relecture humaine – notamment lors du traitement de documents juridiques et de rapports financiers – la solution est une condition préalable pour garantir une gestion documentaire rentable.
Les statistiques réaffirment l'efficacité de la technologie. D'ici 2025, le marché mondial de l'OCR est estimé pour atteindre une valeur supérieure à 22 750 €. Ce sera 14,8 % de plus qu'en 2017. Le nombre d'adoptants est le plus élevé en Amérique du Nord, suivi de l'Europe.
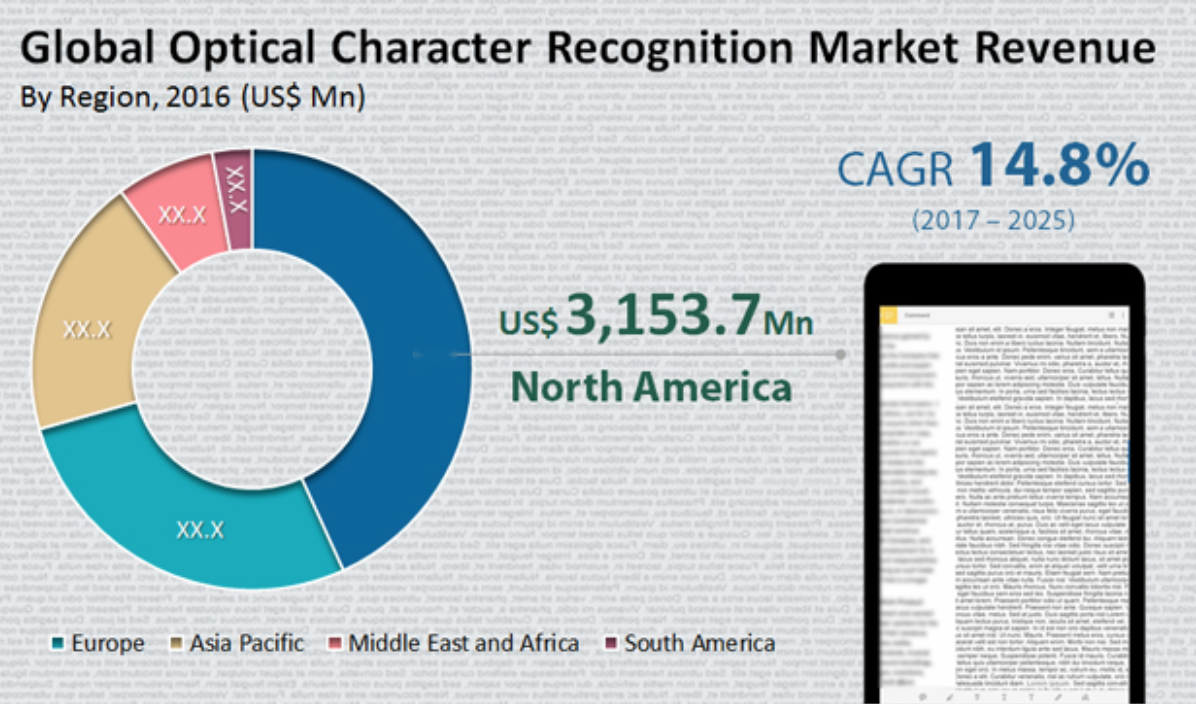 Source : www.transparencymarketresearch.com
Source : www.transparencymarketresearch.com
Une autre approche de la gestion des documents est reconnaissance optique de marques (OMR). La technologie est couramment utilisée pour accélérer et faciliter la capture de données annotées par l'homme. Il s'agit par exemple de résultats de sondages, de tests à choix multiples, de retours clients ou d'enquêtes. Après avoir scanné les documents, l'algorithme détecte l'emplacement et reconnaît les marques manuscrites bien plus rapidement que les employés humains. L'approche technologique permet aux machines d'exécuter les tâches routinières de façon efficace en termes de temps et de ressources et favorise l'automatisation du workflow d’entreprise.
Reconnaissance intelligente de caractères (ICR) vise à résoudre des défis plus sophistiqués. La technologie permet d'apprendre aux machines à traiter| documents bruts manuscrits. Selon les différentes polices et styles, lettres bâtons ou écriture cursive, le niveau de précision peut varier de 50 % à 70 %. Ce taux peut être amélioré grâce à un entraînement supplémentaire de l'algorithme sur des ensembles de données riches et spécifiques.
Source : www.opentext.com
Reconnaissance intelligente de documents (IDR) pour un nombre incalculable de documents
Les processus commerciaux complexes génèrent des volumes de documents non structurés, c'est-à-dire dans le secteur de la finance et de la logistique. L'IDR permet d'extraire des données de n'importe quelle partie d'un document, y compris la méta description. Cette technologie intègre la reconnaissance optique de caractères mais améliore également les capacités de l'OCR. Elle peut interpréter les motifs, les tableaux et le contenu dans les formats papier et électronique, reconnaître le début et la fin des documents, et les classer par catégories en conséquence. Ensuite, toutes les données requises peuvent être extraites et préparées pour être stockées dans une base de données ou utilisées dans des apps métier.
Pour illustrer, IBM Watson a récemment rendu disponible une fonctionnalité pilotée par IDR pour travailler avec des documents métier et de gouvernance. Ces solutions métier sont les plus recherchées ces jours-ci car elles aident à atténuer les risques et à réduire le temps et les coûts pour extraire un maximum de données précieuses et découvrir de nouvelles perspectives métier.
Reconnaissance des codes QR pour une meilleure expérience client
Capture de données automatisée peut être mené via différents systèmes puisque par définition les données existent sous plusieurs formats, par exemple, étant cryptées dans des codes QR. Le nombre de cas d'usage liés dans le commerce de détail et le paiement en magasin est en plein essor. Des leaders du secteur comme Walmart , Starbucks , et Amazon ont transformé la technologie en une solution novatrice pour capturer des données sur les marchandises et effectuer des paiements.
On prévoit que Amazon Go changera la façon traditionnelle de faire ses courses. Chaque visiteur est invité à télécharger l'application et à scanner le code QR fourni à l'entrée pour effectuer des achats dans un magasin sans caisses. C'est l'une des méthodes de capture de données utilisées pour alimenter le système scan-and-go.
Pour promouvoir la torréfaction et permettre aux amateurs de café d'en apprendre davantage sur leurs boissons favorites, Starbucks place des QR codes dans ses points de vente et sur des prospectus, invitant les consommateurs à scanner un code et à être redirigés vers des informations sur les produits café, y compris des avis d'experts ou même de la musique de la région de culture.
Le plus grand détaillant des États-Unis, Walmart, utilise des codes QR pour permettre l'auto-service. Dans les grandes surfaces commerciales, plusieurs caisses en magasin permettent aux clients de scanner le code via une application mobile et de payer leurs achats avec leurs smartphones.
Voice Recognition pour des interactions fluides
D'ici 2020, la recherche vocale devrait représenter 50 % de toutes les recherches sur le web, selon Econsultancy. Les assistants vocaux comme Google Assistant, Siri, Alexa, Cortana disposent de la technologie de traitement du langage naturel (NLP) sous le capot. Un simple « Hey Google » ou « Alexa » réveille le système pour déchiffrer la commande puis y obéir ou générer une réponse.
 Source : www.forbes.com
Source : www.forbes.com
Les approches NLP de pointe sont basées basé sur des algorithmes de deep learning qui nécessitent d'énormes quantités de données étiquetées pour reconnaître et comprendre les schémas vocaux, numériser la parole humaine et traiter la Big Data afin de réagir de manière humaine.
En plus de tels domaines populaires d'implémentation technologique comme interprétation, services de support, marketing ou sécurité, le NLP peut être intégré dans des systèmes de capture de données électroniques. De telles solutions aident à agréger les données des essais cliniques ou les données des patients qui peuvent être saisies manuellement ou par la voix.
Points clés à retenir
Parmi les avantages de la capture automatisée des données, il y a des approches économes en temps et en coûts pour la collecte et le traitement des données avec peu ou pas d'intervention humaine, des moyens accélérés pour récupérer des informations, prédire des risques ou découvrir des perspectives, une expérience consommateur améliorée, une recherche facilitée, et plus encore. En ce qui concerne les inconvénients, les processus de capture automatisée des données ne sont pas infaillibles, mais le taux d'erreur s'améliore continuellement.
Les entreprises de tout type doivent adopter une méthode de collecte et de traitement de la Big Data. Coopérer avec un partenaire fiable fournisseur de capture de données automatisée, ils peuvent devenir propriétaires de solutions haut de gamme répondant à des exigences spécifiques à une niche. C'est précisément la clé du succès sur un marché d'aujourd'hui hautement concurrentiel.
Développons un Système personnalisé de capture de données automatisée
Vous cherchez une entreprise technologique pour vous aider avec la capture et la collecte automatisées de données, planifier un appel avec notre équipe expérimentée de data scientists et d’ingénieurs.


