
La collecte de Big Data est la clé des processus commerciaux modernes. Mais comment les entreprises collectent-elles la Big Data ? Nous allons bientôt le découvrir.
D'ici 2025, les experts s'attendent à un afflux de plus de 463 exaoctets de données par jour. Si nous traduisons cela en DVD (vous vous en souvenez ?), cela représente plus de 212 millions d’entre eux. Ainsi, les entreprises ont besoin d’un écosystème robuste de collecte et d’analytique pour donner un sens à cette avalanche d’informations. Cette demande aiguë a donné naissance à de nombreux outils et techniques de collecte de Big Data.
Cela dit, passons en revue le processus de collecte de la Big Data. Nous aborderons également les méthodes et outils de collecte de Big Data les plus populaires.
Qu'est-ce que la Big Data et pourquoi est-elle importante ?
Nous rencontrons souvent ce phénomène aujourd’hui. Ce terme sophistiqué désigne une combinaison de données structurées et non structurées arrivant à grande vitesse et en très grand volume. Cependant, les outils de traitement traditionnels sont incapables de discerner ces informations. C’est pourquoi les entreprises utilisent des outils robustes de collecte de Big Data pour transformer ces données en statistiques, analyses, prévisions et aide à la décision.

Source : Unsplash
La Bigdata aide également à analyser tous les facteurs pertinents et à prendre la bonne décision. Il aide à construire des modèles de simulation pour tester votre décision, idée, ou produit. C'est la raison principale pour laquelle 97,2 % des entreprises investissent dans intelligence artificielle et la Big Data.
Entreprises de collecte de Big data puiser l’entrée d’un éventail de sources, notamment :
- Internet des Objets (IoT) et appareils connectés ;
- réseaux sociaux, blogs et médias;
- données de l’entreprise, y compris les transactions et les profils clients ;
- relevés d’outil tels que ceux des stations météo
- données de santé tels que les EMR et l'imagerie médicale.
Pourquoi la Big Data est-elle importante par ailleurs ?? Voyons voir.
Avantages de la collecte de données des grandes entreprises technologiques
La collecte de Big Data ne se résume pas à la quantité d'informations. L'importance réside dans la manière dont les entreprises l'exploitent. Ainsi, les systèmes analytiques aident les organisations à découvrir des insights cachés dans les matériaux et à identifier de nouvelles opportunités commerciales.
Économies de coûts
Au sommet de la liste des avantages figure la réduction des coûts. La Big Data est un grand coupe-coûts grâce à sa capacité de pronostic. Cet avantage est visible dans| Les cas d'usage de la Big Data dans le commerce de détail où il|elle est utilisé(e) pour réduire les coûts de retour produit. Habituellement, le|la le coût des retours de produits est presque deux fois plus élevé que celui de l'expédition elle-même. C'est pourquoi les détaillants cherchent toujours des moyens d'optimiser leurs dépenses. Les outils de collecte de big data peuvent identifier les articles les plus susceptibles d'être retournés. Ils permettent aux entreprises de prendre des mesures proactives pour minimiser les pertes et réduire les coûts.

Source : Unsplash
Meilleure prise de décision
La collecte de Big Data couplée à l'analyse en temps réel nous permet de traiter rapidement les nouvelles tendances. Les outils de collecte de Big Data comme Hadoop aident les entreprises à générer des insights immédiatement. Cela se traduit par une prise de décision plus rapide et plus intelligente. Un exemple frappant est l'utilisation de La Big Data dans la médecine.
Un livre blanc de Intel se penche sur la manière dont quatre hôpitaux utilisent des données provenant de diverses sources. Il les aide à prévoir les charges hospitalières quotidiennement et heure par heure.
Prévention de la fraude
Le Data et l'Analytics peuvent également aider les entreprises à obtenir des informations exploitables pour éviter la fraude. Par exemple, les organisations peuvent traiter les tendances des consommateurs pour identifier et prévenir des activités suspectes. Ainsi, les systèmes peuvent signaler même les petites différences dans une activité de crédit comme une fraude potentielle.

Source : Unsplash
Ventes accrues et meilleure expérience client
Entreprises de Data Analytics aux États-Unis ont également aidé les agences à mieux définir les produits et services. La diversité des informations renforce tous les niveaux du processus de vente. Elle améliore la précision des campagnes marketing et la qualité des données de prospects. De plus, les flux d'informations en temps réel permettent d'identifier| sentiment client. Cela, à son tour, intègre les retours clients dans le processus de prise de décision.
Dans l'ensemble, la collecte de flux d'informations dynamiques favorise la croissance des entreprises. En établissant une vue d'ensemble des processus, les organisations peuvent utiliser divers types de données à leur avantage.
Top des méthodes de collecte de Big Data
Typiquement, l'architecture de collecte de la Big Data tourne autour de types spécifiques d'informations. Cela inclut :
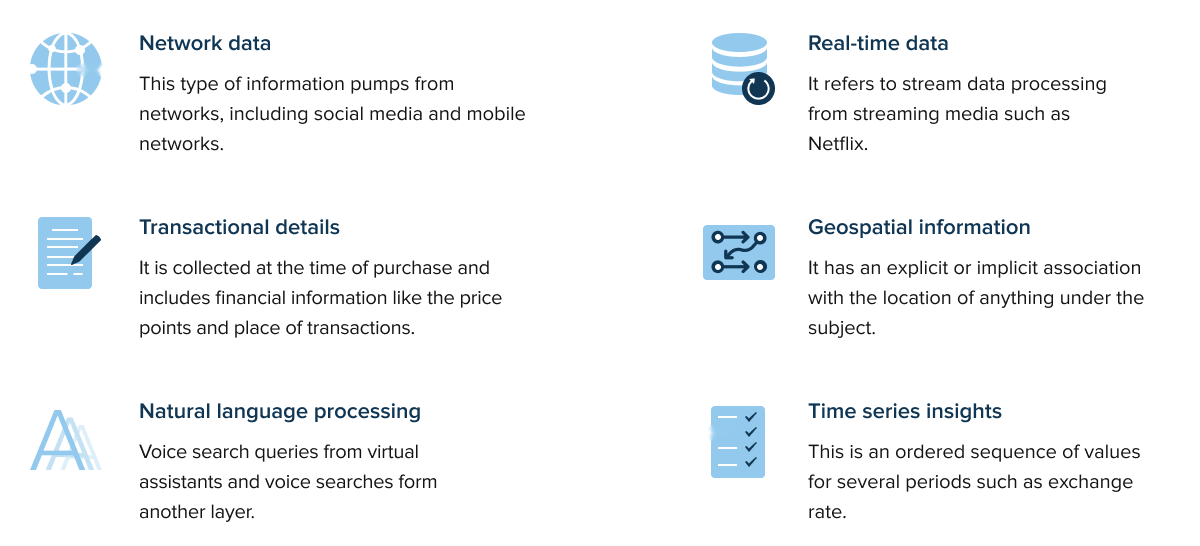
Ce lot d'informations est ensuite alimenté dans des systèmes analytiques pour générer des insights précieux. Plus une organisation collecte d'informations sur les préférences d'un utilisateur, mieux les algorithmes peuvent transformer ces informations en actions. Mais comment les entreprises les collectent-elles ? Aujourd'hui, il existe plusieurs exemples de collecte de Big Data.
Nous examinerons ci-dessous les plus populaires.
Demander directement à vos clients
Dans la plupart des cas, les entreprises demandent aux utilisateurs la permission d'utiliser leurs informations personnelles. Cela prend généralement la forme d'une politique de confidentialité. Elle détaille les méthodes de l'entreprise pour collecter des informations clients électroniques.
Cookies
Les cookies sont de petits fichiers texte qui stockent des informations sur nos actions précédentes sur les sites web. Ils peuvent inclure les préférences de l'utilisateur, les éléments vus et le texte saisi. Les cookies recueillent également l'adresse IP de l'utilisateur, sa localisation ainsi que la version du système d'exploitation et du navigateur.
Suivi des emails
Cette source d'insights fait référence à la surveillance des ouvertures et des clics d'emails. Cela aide les entreprises à suivre les offres, les partenariats, et autres. La plupart des outils de suivi d'emails capturent des données sur les taux d'ouverture et l'interaction des utilisateurs, ce qui informe les décisions marketing.
Source : Unsplash
Cartes de fidélité
Il s'agit d'un système d'incitation où les clients accumulent des crédits pour des réductions futures. Les programmes de fidélité récompensent et encouragent les clients réguliers. Plus important encore, il stocke votre historique d'achats. Cela signifie que les cartes aident les détaillants à comprendre le comportement des consommateurs. Ensuite, elles le façonnent en ciblant des publicités et des offres spéciales.
Gameplay
Game data is another example of Big data collection techniques. By including analytics in the game, companies can assess players' behavior. In-app purchases, game deletion, failed levels – all of these are tracked by a company. The insights are then used to enhance the gameplay.
Un exemple frappant d'infrastructure Big Data puissante est celui des géants technophiles tels que Amazon et Apple. Ils collectent des informations pour créer une vue « 360 degrés » de leurs clients. Ils transforment les insights en moteurs de personnalisation et offrir des expériences d'achat personnalisées.
Comment la Big Data est-elle collectée (étape par étape) ?
Les données brutes sont comme des diamants. Avant de devenir des pierres précieuses, elles doivent passer par plusieurs étapes d'exploitation, de concassage et de nettoyage. De même, les informations aléatoires n'ont aucune valeur. Les Big data à valeur ajoutée doivent être bien structurées, nettoyées et analysées. Voyons les principales étapes de la collecte des Big data.
Étape 1 : Extraction/Récupération
Cette étape déploie le cycle. Elle consiste à récupérer des données non structurées ou mal structurées provenant de diverses sources. Elles sont ensuite envoyées vers des lieux centralisés pour être stockées ou traitées davantage. Les sources non structurées peuvent inclure des pages web, des emails, des documents, des fichiers PDF, des textes scannés, et d'autres. Le stockage centralisé peut être sur site, basé sur le cloud, ou hybride. Cependant, cette étape ne comprend pas le traitement ou l'analyse des données. Les organisations peuvent également acheter des données auprès d'entreprises DaaS et utiliser outils d'extraction de la data.

Source : Unsplash
Étape 2 : Collecte
En général, cette étape est similaire à la première. Dans ce cas, c'est une approche constante et systématique de collecte et de mesure d'informations à partir de diverses sources. Contrairement à la première étape, elle est réalisée régulièrement pour obtenir une vision complète et précise d'un domaine d'intérêt.
Étape 3 : Stockage
Ensuite, vous aurez besoin d'une architecture de calcul et de stockage pour gérer des ensembles de données à grande échelle. Il existe trois principales façons de stocker une telle quantité de données. Les disques durs, RIAD, etc. sont parmi les plus populaires en raison du coût plus bas des médias. Les entreprises utilisent également des clouds publics et privés.
De plus, le stockage est disponible avec des systèmes basés sur des objets et des fichiers. Ce dernier ne limite pas les capacités spécifiques et permet des tailles de plusieurs téraoctets ou pétaoctets.
Étape 4 : Nettoyage
Cette étape aide à éliminer les erreurs et incohérences survenues dans la base de données. Lors de la combinaison de plusieurs sources, les doublons ou les éléments mal étiquetés sont courants. De plus, les informations erronées affectent la précision des algorithmes et la valeur analytique.
Il n'existe pas beaucoup de façons de nettoyer des données d'une telle ampleur. Le plus grand obstacle est sa variété. Différents types d'erreurs comme l'incomplétude et les conflits de valeurs peuvent coexister et affecter le résultat de l'analyse. KATARA, Algorithmes ML, et les systèmes de nettoyage parallèles sont quelques exemples de systèmes de nettoyage Big Data.
Étape 5 : Réorganiser les données
La prochaine étape consiste à réorganiser les informations pour une utilisation plus pratique. La réorganisation vise à améliorer la performance du système et à récupérer l'espace mémoire. Elle aide également les ingénieurs améliorent la disponibilité des données, performances des requêtes et temps de réponse. Cette procédure est particulièrement importante pour les environnements de charges de travail critiques.

Source : Unsplash
Étape 6 : Vérifier les données
Vérifier la précision des entrées est une autre étape importante dans le cycle de vie. Le processus de vérification est ce qui garantit la cohérence et un objectif clair. En fonction de vos exigences, vous pouvez effectuer une vérification complète ou une vérification par échantillonnage. Dans ce dernier cas, un petit échantillon de données est vérifié, ce qui prend moins de temps.
Étape 7 : Analyse
Recueillir des actifs précieux est une étape importante dans le cycle de vie des données de toute entreprise. Cependant, il ne suffit pas d'accumuler des informations en temps réel. Vous devez également les traiter pour tester vos hypothèses commerciales ou une ligne de conduite. Pour ce faire, vous pouvez exploiter l'une des méthodes de collecte de Big Data les plus populaires.
Data mining
Cette méthode cible des modèles précédemment inconnus dans de grandes quantités d'informations. Elle est également accompagnée de méthodes statistiques et mathématiques. Pour les entreprises, le data mining est un outil précieux qui identifie les modèles et les relations dans les données pour favoriser la prise de décisions.
Cette méthode est l'une des plus répandues et s'applique à un grand nombre d'industries. Les banques utilisent souvent cette méthode pour analyser les transactions pour détection de fraude ou la probabilité de remboursement de prêts.

Source : Unsplash
Analyse des clusters
Cette méthode d'analyse suppose de regrouper des objets en clusters en fonction de leur degré de similarité. Les objets de la classification sont des observations. Celles-ci peuvent inclure des consommateurs, des pays, des articles, et d'autres. Ainsi, le principal objectif de l'analyse de clusters est de trouver des groupes d'objets similaires dans un échantillon.
Cette méthode est largement utilisée dans de nombreuses applications. Cela inclut la recherche de marché, la reconnaissance de motifs et le traitement d'images. Elle peut également aider les marketeurs à discerner des groupes distincts dans leur base de clients.
Réseaux de neurones
Ce domaine de la discipline pose les bases pour le smart capacités du machine learning. Cette méthode d'analyse vise à imiter la puissance de traitement du cerveau humain et à prédire des valeurs avec une implication minimale. Comme les réseaux de neurones apprennent de chaque transaction de données, ils évoluent et s'améliorent avec le temps. Ils constituent un outil prédictif indispensable, largement utilisé de la prévision et de la recherche marketing à la détection de fraudes et à l'évaluation des risques.
Étape 8 : Visualisation
Dernier point, mais non des moindres, concerne la représentation graphique des insights obtenus. Cette étape est généralement renforcée par des outils de visualisation et peut prendre la forme :

En visualisant les informations, vous fournissez un rapport digeste qui transmet le message à un public plus large à l'intérieur et à l'extérieur de l'organisation. Le format du rapport peut varier en fonction de la nature des informations et de l'entreprise.
Ce n'est pas une étape obligatoire pour tous les projets de data. Cependant, cette phase reste importante pour boucler un cycle de vie de la data efficace. Les blocs d'une stratégie de Big Data peuvent varier selon la complexité des données, les besoins métiers et le domaine d'application. Mais voici les 8 étapes de base pour gérer des couches d'information massives.
Le dernier mot
La collecte et l'analyse du Big data ouvrent une multitude d'opportunités sans précédent pour les organisations. Elles aident à tirer le meilleur parti des faits et des chiffres entrants ainsi qu'à identifier des zones de croissance. Cela conduit à des décisions commerciales intelligentes, des processus plus efficaces, des profits plus élevés et des clients satisfaits.
Mais pour stimuler l'intelligence des données, les entreprises doivent mettre en place une stratégie de collecte cohérente. Celle-ci implique plusieurs étapes de collecte, de nettoyage et d'analyse du contenu. En conséquence, une stratégie bien entretenue se transforme en un cycle vertueux de données complet qui assure une boucle auto-renforcée d'insights métier.
Solutions de collecte de data par DataSqueeze
Besoin d'aide pour la collecte et l'analyse de données ? Planifier un appel, et nos spécialistes vous conseilleront sur les meilleures méthodes de collecte de données pour votre projet.


